Timbre
Press record and hum or sing some simple tune without words (go la-la-la). An AI will transform the sound of your voice into the selected instrument. (Instead of singing, you can also play a flute or some other instrument that plays a single note at a time.)
Timbre is the characteristic that allows us to differentiate the same note, with the same volume, played on two different instruments.
The AI is composed of two neural networks. The first encodes the input to pitch and volume data, removing the timbre, in a way. The second is a decoder trained with many hours of recorded performances. It can take the output from the encoder and create a sound file based on the same frequencies and volumes, but with a different timbre. We use a different decoder for each instrument.
Splitting an input into “content” and “style” and then switching the “style” part is a common and novel application of neural networks. There are many “style transfer” apps that allow you to give an input image the style of a famous painter. Also, the deepfake technology works similarly by encoding a face into a simplified representation and decoding it with a network trained on the face of another specific person.
Up ahead, we’ll
Revealing overtones
The pitch of a sound can be described quite precisely by a frequency in hertz. The volume can be measured in decibels. Timbre is more complex; we often describe it metaphorically with words such as bright, hollow, round, sharp, or brassy (among many others). A violin and a trumpet have different timbres, but different violins can also have different timbres, depending on their material or shape.
Another way to think of timbre is as the “shape” of the sound wave. The simplest sound wave is the sine wave (like the one produced by oscillators in a synthesizer), which is produced by a uniform back-and-forth vibration. But acoustic instruments have more complex physics. For instance, a vibrating violin string follows a triangular whip-like movement, which creates a more complex wave.
The way we make the string vibrate, and the way it’s attached to the instrument, produces “overtones,” which you can think of as additional vibrations in higher frequencies. Each musical instrument produces a set of overtones with different frequencies, and this combination gives it its color. The construction of the instrument affects the sound further. For example, the body of a violin will amplify certain overtones and dampen others, depending on its size, shape, and material. Finally, we also identify the sound of instruments based on how their soundwaves change through time, e.g., a cymbal has a sharp and loud attack but then keeps resonating with a different color for a longer time.
The evolution of samplers
Right from the start, electronic music tried imitating the timbre of acoustic instruments. One early strategy was to use oscillators and filters to construct a soundwave with the same overtones as an acoustic sound. Then, apply an “envelope” that changes the sound’s volume or frequencies as time passes, imitating how the sound evolves in a physical instrument.
This technique allowed the creation of an extensive range of synthesized timbres. These are the sounds we associate with the 80s, electronic music, and retro video games. They are reminiscent of the acoustic instruments that inspired them, but they’re unrealistic.
As technology advanced, synthesis became more sophisticated, but it raced against the development of an alternative strategy: working with recordings.
The Mellotron is an iconic electro-mechanical instrument. It’s played via a piano-like keyboard. When we press a key, a magnetic tape with a recorded sound begins playing. When we release the key, a spring pulls back the tape to its starting position. Tapes can be switched to access different sounds, and the tape playback speed can be changed to adjust the pitch.
Using turntables as a musical instrument dates back to the 1930s, but Hip Hop artists in the 80s took it to a whole new level of popularity. They developed techniques like looping parts of songs, scratching, and mixing the percussion from one record with a melodic section of another. Sound collages, also a very early technique, became a standard production technique in popular music.
The Fairlight CMI, released in 1979, was the first commercially available polyphonic digital sampler. It was a very expensive system with synthesizer and digital audio workstation capabilities. It used floppy disks to store low-quality samples. It promised an “orchestra-in-a-box” by including eight disks that had 22 samples of orchestral instruments each.
The E-mu Emulator, from 1981, became very popular with musicians because of its lower price and more portable size, which allowed using it live. A second version released a few years later improved the sound quality and provided many pop recordings and movie soundtracks of the time with a broad palette of sounds, like the Shakuhachi flute in Peter Gabriel’s “Sledgehammer.”
Modern sampler software can include many gigabytes of high-quality recordings of an instrument playing every note in different ways. A common alternative is virtual instruments that simulate how acoustic instruments produce sound through complex physics models. They can be incredibly faithful but depend on our ability to enumerate the laws and physical processes that affect the sound production. One advantage of using AI for the task is that neural networks can learn to reproduce the shape of the sound waves of the instrument we want to imitate simply by training with examples, without programming in them any knowledge of physics.
How does our AI work?
The neural networks in other chapters (like the ones about “Melody” or “Rhythm”) produce sequences of notes. You can think of these sequences as sheet music or MIDI files. These notes are then played with a synthesizer or sampler in your browser to produce sound. The neural network on this page does something different.
This neural network is connected to a series of Digital Signal Processors (DSP) software components that, like traditional oscillators and filters, can produce and modify sound waves. The sound of any instrument (e.g., a trumpet) could, in theory, be reproduced by creating a wave with the right shape. Back at the beginnings of electronic music, oscillators and filters were operated by humans manually, which limited how precisely or quickly sound waves could be shaped.
By training with examples of the timbre we want to reproduce, our neural network learned to precisely control the parameters in the DSPs. Every few milliseconds, the neural network tweaks the parameters of oscillators, filters, noise generators, and reverb to generate the sound wave that you can hear through your speakers. You can imagine this as operating the multiple knobs in a classic analog synthesizer, like the Moog, at superhuman speed.
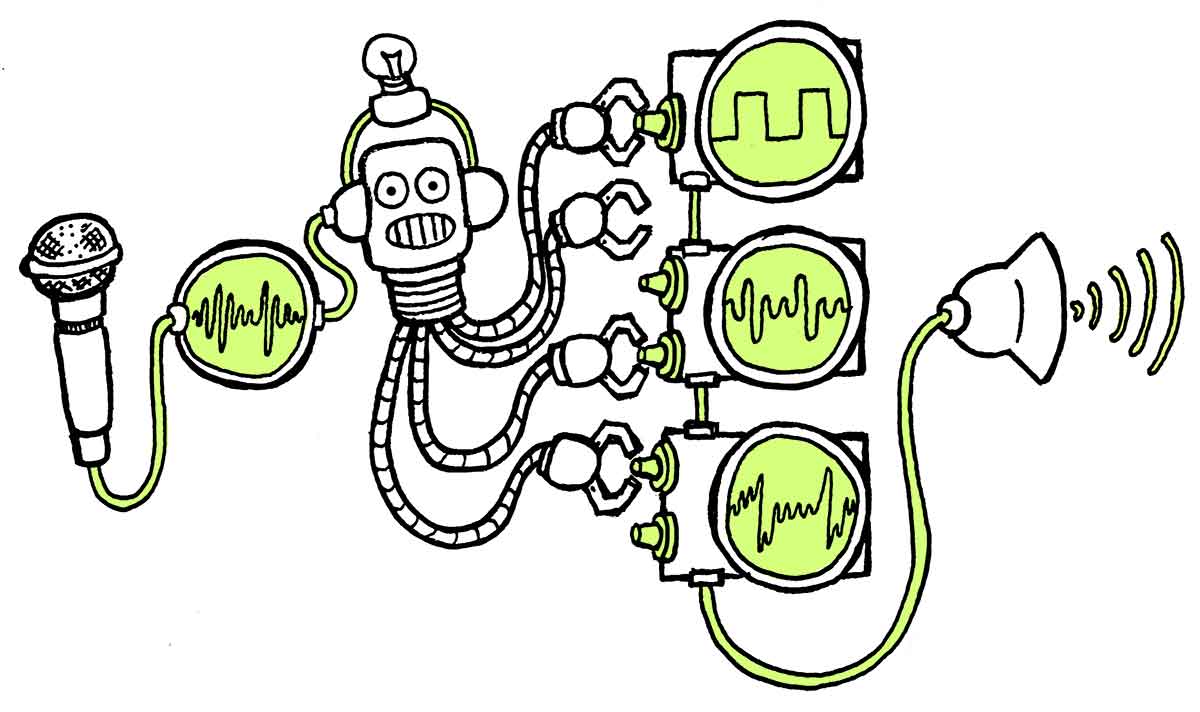
For each instrument whose timbre we want to reproduce, we use a different neural network. These networks all have the same architecture but were trained with different examples. Thus, they generate a different output when given the same input recording.
Food for thought
We describe timbres through metaphors and words that suggest visual and tactile information, like “round,” “hollow,” or “deep.”
How can we use AI to create new timbres that match the feelings and sensations we want to work with? Besides words, in what other ways could we give the AI prompts to design unique timbres?
External links
- Play with the full version of Google Magenta’s Tone Transfer, which features extra options, examples, and explanations.
- See the source code in our Github repository.
Credits
Google Magenta’s Tone Transfer was created by the Magenta and AIUX team within Google Research.
Models used in this demo were made possible with training data provided by the following musicians and organizations, as credited by Google:
Violin: Musopen (Creative Commons)
Flute: Musopen (Creative Commons)
Trumpet: University of Rochester
Saxophone: Kevin Malta
Copyright and license information can be found in our GitHub repository.
References
- Jesse Engel, Lamtharn (Hanoi) Hantrakul, Chenjie Gu and Adam Roberts. DDSP: Differentiable Digital Signal Processing. International Conference on Learning Representations. 2020
- Gordon Reid. “Synthesizing Bowed Strings: The Violin Family.” Synth Secrets. Sound on Sound magazine. 2003-04. Retrieved 2022-11-15.
- Wikipedia contributors. “Sampler (musical instrument)“ Wikipedia, The Free Encyclopedia. 2022-12-27. Retrieved 2022-12-28.
- Wikipedia contributors. “Mellotron.” Wikipedia, The Free Encyclopedia. 2022-12-21. Retrieved 2022-12-22.
- Wikipedia contributors. “E-mu SP-1200.” In Wikipedia, The Free Encyclopedia. 2022-12-09. Retrieved 2022-12-21.
Text is available under the Creative Commons Attribution License . Copyright © 2022 IMAGINARY gGmbH.